- Take backup of these 2 tables from backup db:
- dbo.tbl_TestRun
- TestResult.tbl_TestResult
- You can use export/import wizard of ssms
- Specify: sourceServer/database and destinationServer/database

- Select write query to data transfer

- Write sql query to fetch data fromm backup db. And make sure sql query is valid.

- Sample for tbl_testrun table ( It will copy all test runs of backup db to destination db. Make sure you should not copy RV column)
select
PartitionId, TestRunId, Title,CreationDate,LastUpdated,Owner,State,IncompleteTests,DataspaceId,TestPlanId,IterationId,DropLocation,BuildNumber,
ErrorMessage,StartDate,CompleteDate,PostProcessState,DueDate,Controller,TestMessageLogId,LegacySharePath,TestSettingsId,
BuildConfigurationId,Revision,LastUpdatedBy,Type,CoverageId,IsAutomated,TestEnvironmentId,Version,PublicTestSettingsId,IsBvt,Comment,
TotalTests,PassedTests,NotApplicableTests,UnanalyzedTests,IsMigrated,ReleaseUri,ReleaseEnvironmentUri,TestRunContextId , MaxReservedResultId, DeletedOn
from tbl_TestRun where PartitionId = 1- Sample for Testresult.tbl_testresult ( it will copy all test results of backup db to destination db, Make sure you should not copy RV column)
select
PartitionId,
DataspaceId,
TestRunId,
TestCaseRefId,
TestResultId,
CreationDate,
LastUpdated,
Outcome,
State,
Revision,
DateStarted,
DateCompleted,
LastUpdatedBy,
RunBy,
ComputerName,
FailureType,
ResolutionStateId,
Owner,
ResetCount,
AfnStripId,
EffectivePointState
from TestResult.tbl_testresult where PartitionId = 1- Select source and target tables for both tables differently


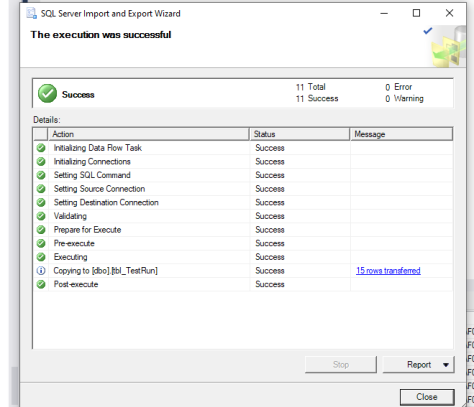
- Make sure export execution is successful
- Identify all partitionid, dataspaceid and planid for which we want to recover test run/results. Use this query for partitioned = 1 :
select ds.PartitionId, pr.project_name, pr.project_id, ds.DataspaceCategory, ds.DataspaceId
from tbl_Dataspace ds
join tbl_projects pr
on pr.PartitionId = ds.PartitionId
and pr.project_id = ds.DataspaceIdentifier
where ds.PartitionId = 1 and ds.DataspaceCategory = ‘TestManagement’ - Execute script updateTestPoints.sql please provide parameter value for @partitionId, @planId, @dataspaceId
ECLARE @partitionId INT = 0
DECLARE @planId INT = 0 — The run’s test plan ID
DECLARE @dataspaceId INT = 0 — The run’s dataspaceId
DECLARE @status INT
DECLARE @rowCount INT
DECLARE @tfError NVARCHAR(255) — used by the macro RAISETFSERROR
IF (@partitionId <= 0)
BEGIN
Select ‘please provide partition id’ as Error
END
— No need to update points if run have no associated plan
IF (@planId <= 0)
BEGIN
Select ‘please provide test plan id’ as Error
END
IF (@dataspaceId <= 0)
BEGIN
Select ‘please provide dataspace id’ as Error
END
IF (object_id(‘tempdb..#ResultHistory’) IS NULL)
BEGIN
CREATE TABLE #ResultHistory
(
PointId INT,
TestCaseId INT,
TestRunId INT,
TestResultId INT
PRIMARY KEY CLUSTERED (PointId)
)
END
TRUNCATE TABLE #ResultHistory
;WITH Points AS
(
SELECT point.PointId,
point.TestCaseId
FROM dbo.tbl_Point point
WHERE point.PartitionId = @partitionId
AND point.PlanId = @planId
AND point.IsDeleted = 0
),
Results AS
(
SELECT point.PointId,
point.TestCaseId,
res.TestRunId,
res.TestResultId,
ROW_NUMBER() OVER(PARTITION BY point.PointId, point.TestCaseId ORDER BY res.TestRunId DESC, res.TestResultId DESC) AS Rows
FROM Points point
LEFT LOOP JOIN TestResult.tbl_TestCaseReference ref
ON ref.PartitionId = @partitionId
AND ref.DataspaceId = @dataspaceId
AND ref.TestCaseId = point.TestCaseId
AND ref.TestPointId = point.PointId
LEFT LOOP JOIN TestResult.tbl_TestResult res WITH (FORCESEEK(ix_TestResult_TestCaseRefId2(PartitionId, DataspaceId, TestCaseRefId)))
ON res.PartitionId = @partitionId
AND res.DataspaceId = @dataspaceId
AND res.TestCaseRefId = ref.TestCaseRefId
INNER LOOP JOIN dbo.tbl_TestRun run
ON run.PartitionId = @partitionId
AND run.DataspaceId = @dataspaceId
AND run.TestRunId = res.TestRunId
AND run.State <> 255
WHERE res.Outcome <> 6
)
INSERT INTO #ResultHistory(PointId, TestCaseId, TestRunId, TestResultId)
— For each point in the plan assigned to @testRunId
— Find the newest non-aborted result and return its date
SELECT PointId,
TestCaseId,
TestRunId,
TestResultId
FROM Results
WHERE Rows = 1
OPTION (OPTIMIZE FOR (@partitionId UNKNOWN, @dataspaceId UNKNOWN))
SELECT @status = @@ERROR
UPDATE dbo.tbl_Point
SET LastTestRunId = ISNULL(res.TestRunId, 0),
LastTestResultId = ISNULL(res.TestResultId, 0),
LastResultState = res.State,
LastResultOutcome = res.Outcome,
State = ISNULL(res.EffectivePointState, 1),
ChangeNumber = ChangeNumber + 1,
LastUpdated = GETUTCDATE(),
LastUpdatedBy = ISNULL(res.lastUpdatedBy, point.lastUpdatedBy),
FailureType = res.FailureType,
LastResolutionStateId = ISNULL(res.ResolutionStateId, 0),
OutcomeMigrationDate = GETUTCDATE()
OUTPUT @partitionId,
INSERTED.PointId,
INSERTED.ChangeNumber,
INSERTED.State,
INSERTED.Active,
INSERTED.FailureType,
INSERTED.PlanId,
INSERTED.LastTestRunId,
INSERTED.LastTestResultId,
INSERTED.TestCaseId,
INSERTED.AssignedTo,
INSERTED.LastUpdated,
INSERTED.LastUpdatedBy,
0, — IsSuiteChanged
0, — IsActiveChanged
INSERTED.LastResolutionStateId,
INSERTED.SuiteId,
INSERTED.ConfigurationId,
GETUTCDATE(),
INSERTED.LastResultOutcome
INTO dbo.tbl_PointHistory
(
PartitionId,
PointId,
ChangeNumber,
State,
Active,
FailureType,
PlanId,
LastTestRunId,
LastTestResultId,
TestCaseId,
AssignedTo,
LastUpdated,
LastUpdatedBy,
IsSuiteChanged,
IsActiveChanged,
LastResolutionStateId,
SuiteId,
ConfigurationId,
WatermarkDate,
Outcome
)
FROM tbl_Point point
LEFT LOOP JOIN #ResultHistory newest
ON point.PointId = newest.PointId
LEFT LOOP JOIN TestResult.tbl_TestResult res WITH (FORCESEEK(ixc_TestResult_TestRunId_TestResultId(PartitionId, DataspaceId, TestRunId, TestResultId)))
ON res.PartitionId = @partitionId
AND res.DataspaceId = @dataspaceId
AND res.TestRunId = newest.TestRunId
and res.TestResultId = newest.TestResultId
WHERE point.PartitionId = @partitionId
AND point.PlanId = @planId
AND point.IsDeleted = 0
OPTION (OPTIMIZE FOR (@partitionId UNKNOWN, @dataspaceId UNKNOWN))
SELECT @status = @@ERROR - You need to execute step 4 multiple times for each different values.
- please take backup of table TestResult.tbl_TestCaseReference Use query similar to this :
Select
ref.PartitionId,
ref.TestCaseRefId,
ref.DataspaceId,
ref.TestCaseId,
ref.TestPointId,
ref.ConfigurationId,
ref.AutomatedTestName,
ref.AutomatedTestStorage,
ref.AutomatedTestType,
ref.AutomatedTestId,
ref.TestCaseTitle,
ref.TestCaseRevision,
ref.Priority,
ref.Owner,
ref.AreaId,
ref.CreationDate,
ref.CreatedBy,
ref.LastRefTestRunDate,
ref.AutomatedTestNameHash,
ref.AutomatedTestStorageHash
from TestResult.tbl_TestCaseReference ref
join TestResult.tbl_TestResult res
on ref.PartitionId = res.PartitionId
and ref.DataspaceId = res.DataspaceId
and ref.TestCaseRefId = res.TestCaseRefId
join tbl_testrun run
on res.PartitionId = run.PartitionId
and res.DataspaceId = run.DataspaceId
and res.TestRunId= run.TestRunId
where ref.PartitionId = 1 — partitionid
and ref.PartitionId = 0 — dataspaceid
and run.TestPlanId = 0 — planid- First check the output of this query on your sandbox server (ideally nothing should be present there)
- Then use sql export wizard to copy this date from backup server to sandbox server and use same query
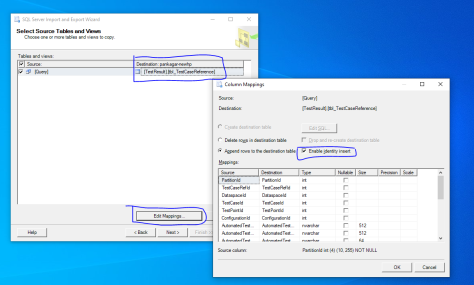
- While selecting source and destination table, click on “Edit Mappings…” and make sure you enable this option: “Enable identity insert”
- Execute step 4 and 5 again